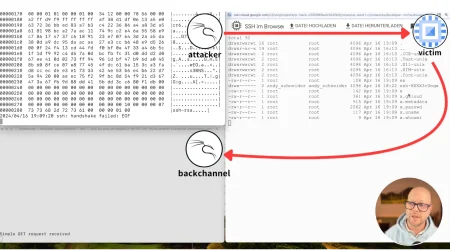
Threat detection and response tools are built on shaky foundations, leaving your cloud workloads at risk
How Lacework Labs uncovered generic evasion techniques that bypass trusted Linux kernel mechanisms

There are several ways to detect threats using system call (syscall) and kernel tracing in Linux. Lacework Labs comprehensively analyzed these mechanisms and their associated risks, and found that cloud workload protection platform solutions offering syscall or other kernel-level monitoring are vulnerable to an attack.
This post will detail the vulnerabilities we found and how attackers can exploit them to avoid detection. We will also provide mitigation strategies to help you protect your workload.
Advanced Threat Detection on Linux
Many cloud workloads run on Amazon EC2 and Kubernetes while most run on Linux. Cloud workload protection solutions that provide advanced threat detection capabilities typically offer syscall monitoring. All significant actions the application performs require syscalls, therefore, malicious activities can be detected by applying detection logic to the syscalls and their corresponding arguments.
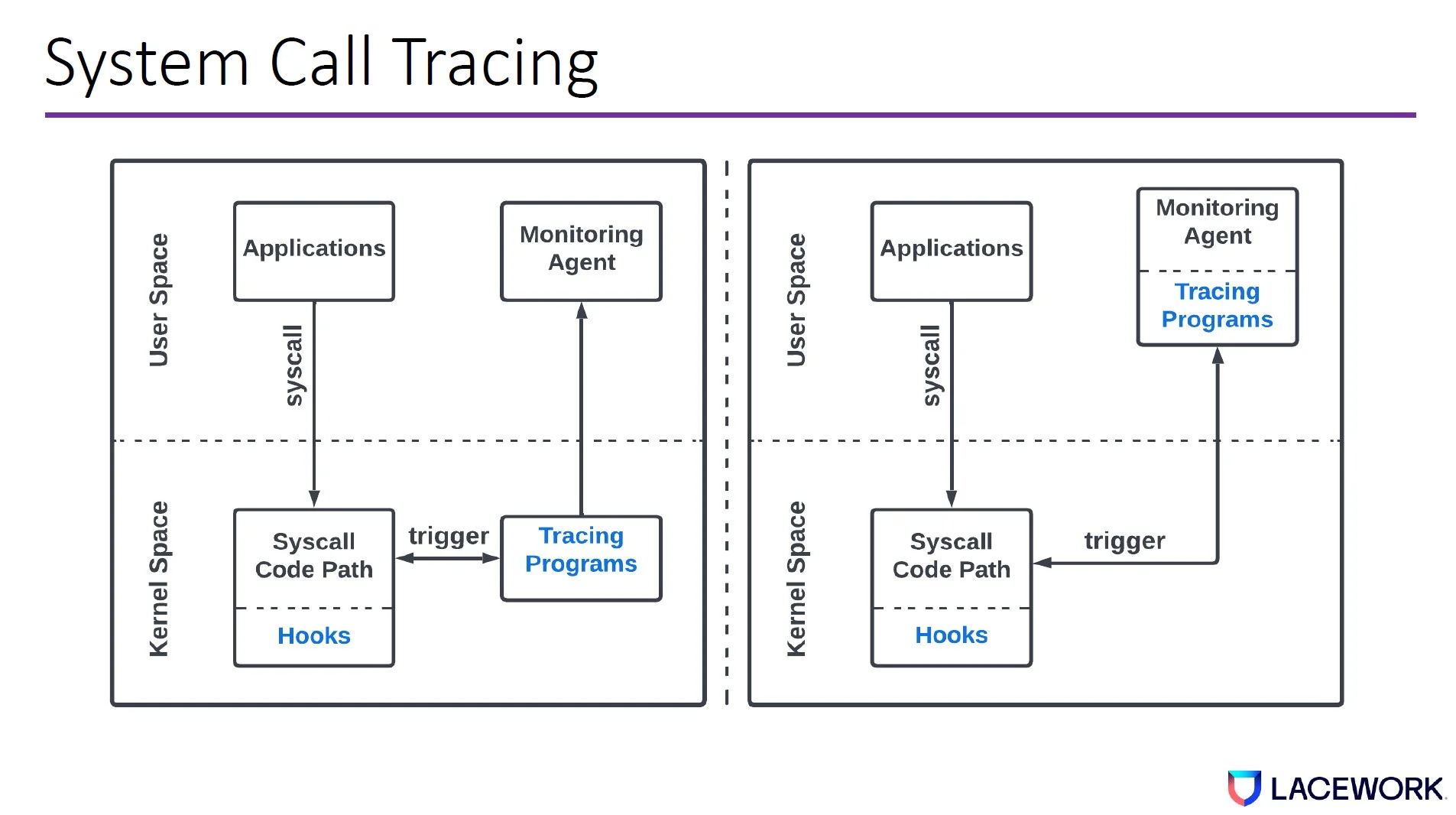
In modern Linux kernels, there are three main ways to monitor syscalls:
- Tracepoint
- Kprobe
- Ptrace
Syscalls can be monitored both at syscall enter and syscall exit. Based on the monitoring mechanisms, tracing programs can be deployed as kernel modules, eBPF programs, or user space programs.
The Shaky Foundation
When a tracing program is executed, it knows the syscall name and reads the syscall arguments. Most high value signals that help detect threats are typically pointer arguments—i.e., a pointer pointing to the user space memory that contains the syscall argument data structure. Pointer arguments typically contain the most important context for threat detection.
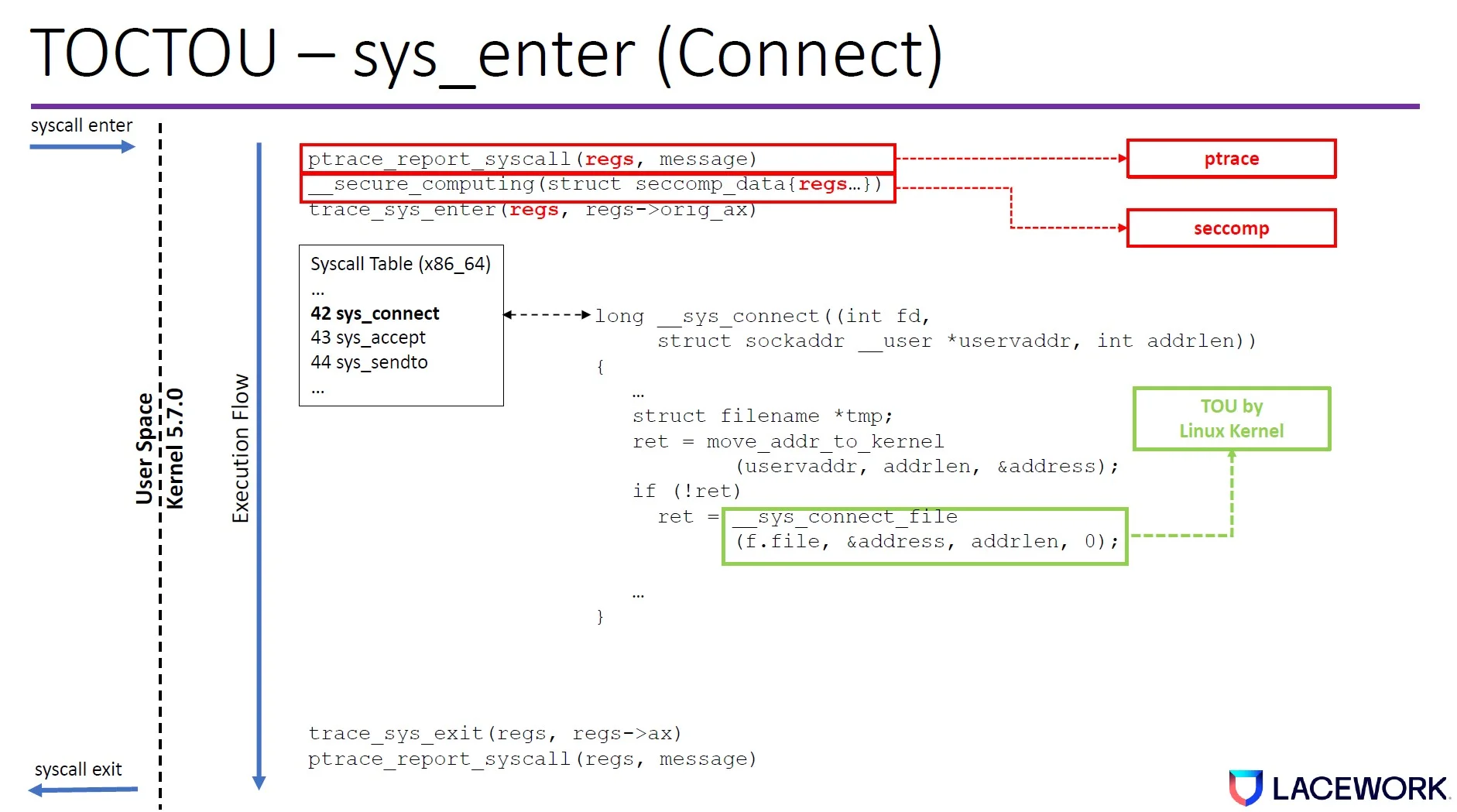
We discovered that both tracepoint and ptrace have time-of-check to time-of-use (TOCTOU) issues at sys_enter and sys_exit. The tracing program dereferences the user space memory in a different amount of time than the kernel both at sys_enter and sys_exit.
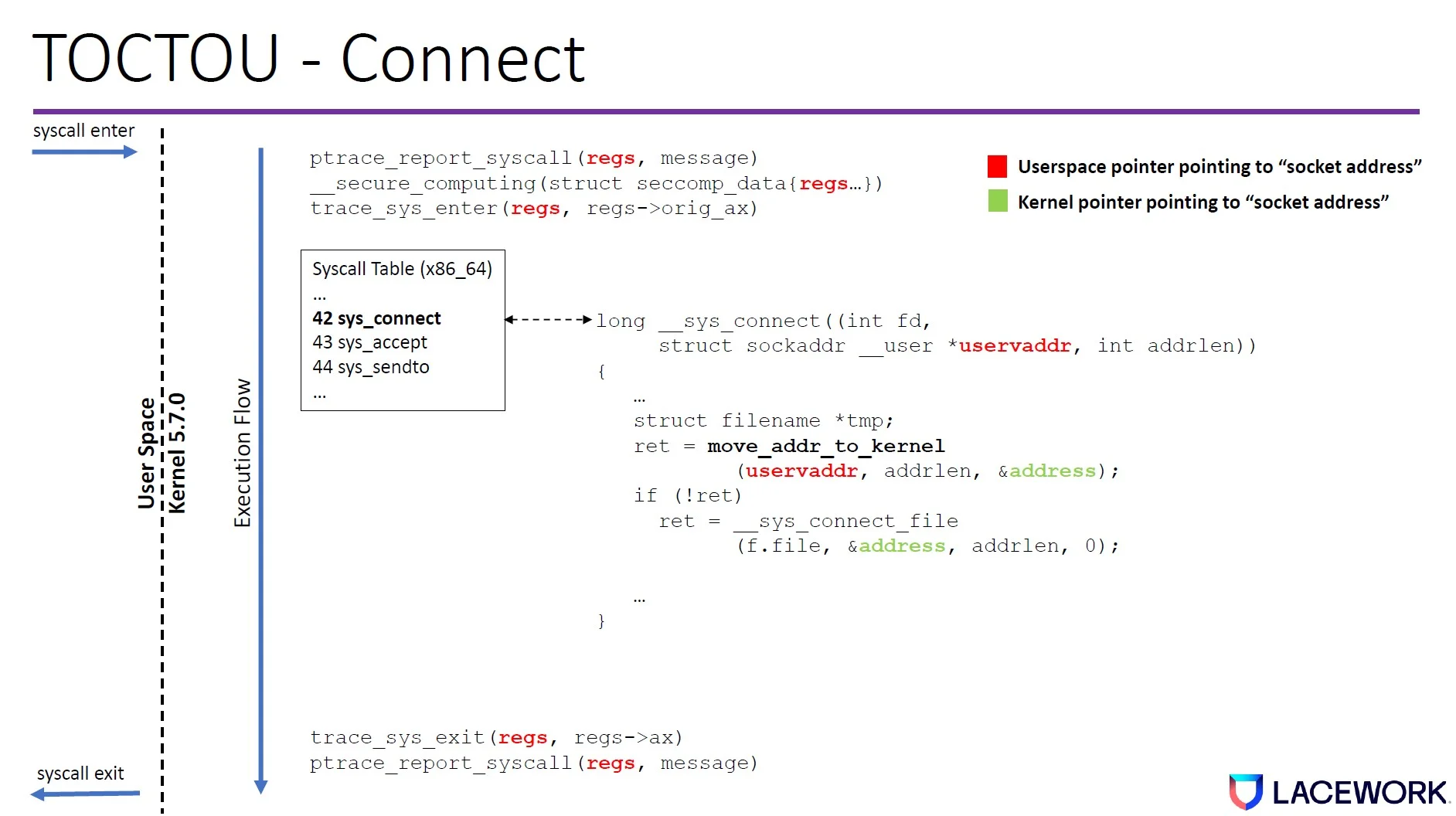
Figure 2. TOCTOU window in the Linux kernel code path (connect syscall example)
This creates a time gap where an attacker can change the memory value so the Linux kernel will execute something different from what the tracing program reports.
These TOTOU windows exist across Linux kernel versions because of how they are designed.
The Previous Exploits
We previously exploited such issues at 2021 DEF CON for both Falco and Tracee. The exploitation technique can be used to inject a delay in the syscall execution. One exploitation primitive we used is the userfaultfd system call. This syscall can be blocked by the default docker seccomp profile. It can be detected if the tracing program monitors this syscall, although none of the tracing software we analyzed monitored such syscalls at the time.
The State-of-the-Art Exploits
Our research team found that we didn’t need to leverage any syscalls to make the bypass—instead, we could leverage syscall’s design, allowing us to inject a long delay to reliably bypass syscall monitoring. There are two ways to accomplish this:
- Blocking condition
- Secure computing mode (seccomp)
Blocking Condition
Blocking condition is when certain syscall executions are blocked. Many syscalls can be blocked because the operating system needs to wait for the underlying resources to respond. These include networking, file system, and other IO operations.
Case study 1: Networking syscalls
Attackers can introduce blocking conditions to bypass the connect syscall. For example, say we have two machines—client and server—and the client runs a program that issues the connect syscall to connect to the server.
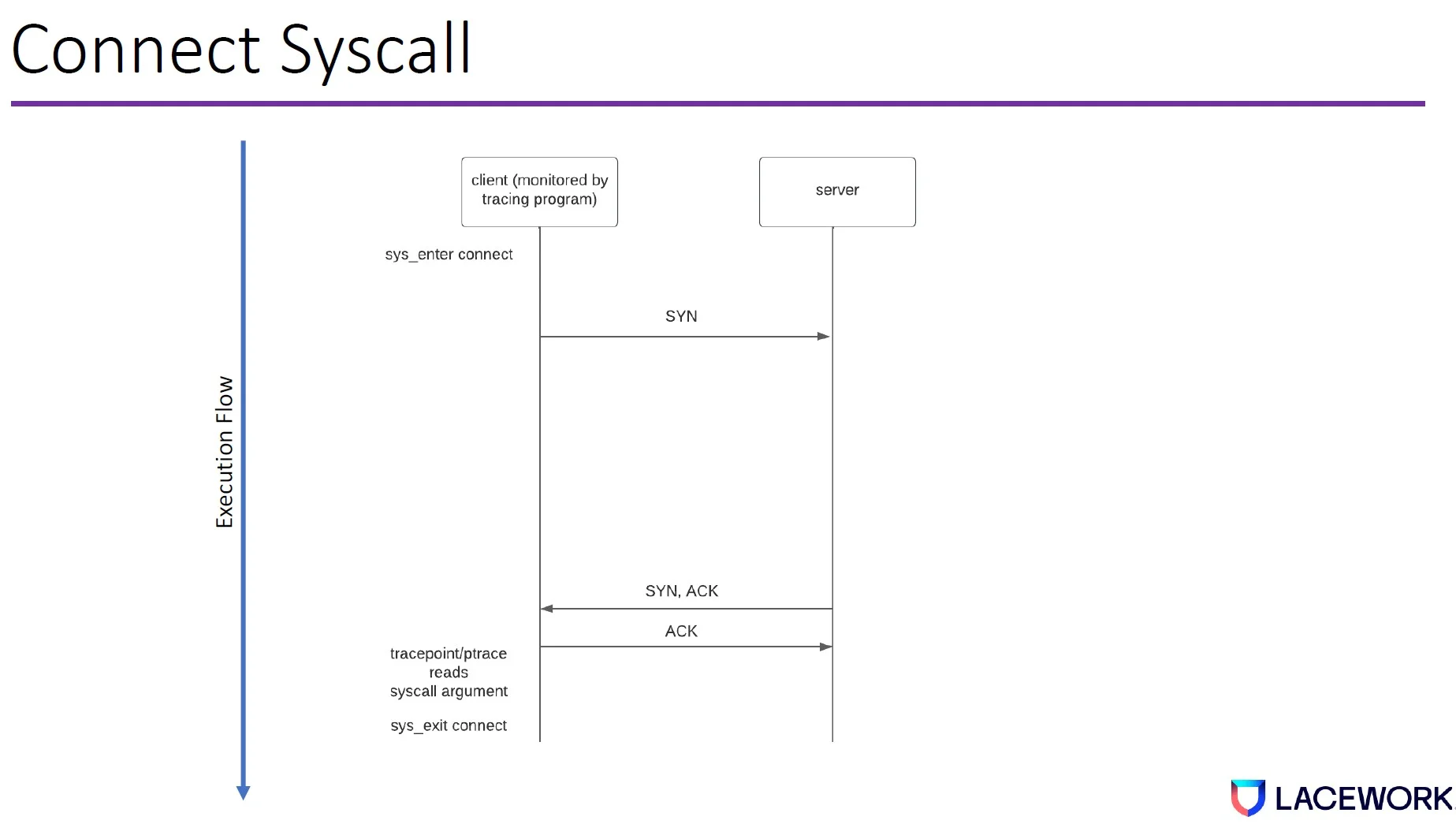
Once the connect syscall starts to execute, the kernel networking stack will allow the hardware to send synchronize (SYN) packets from the client to the server. The server will respond SYN, ACK (acknowledge). Then the client will respond ACK. Once the client program sends out the ACK, the tracepoint or ptrace reads the syscall arguments before the syscall exits.
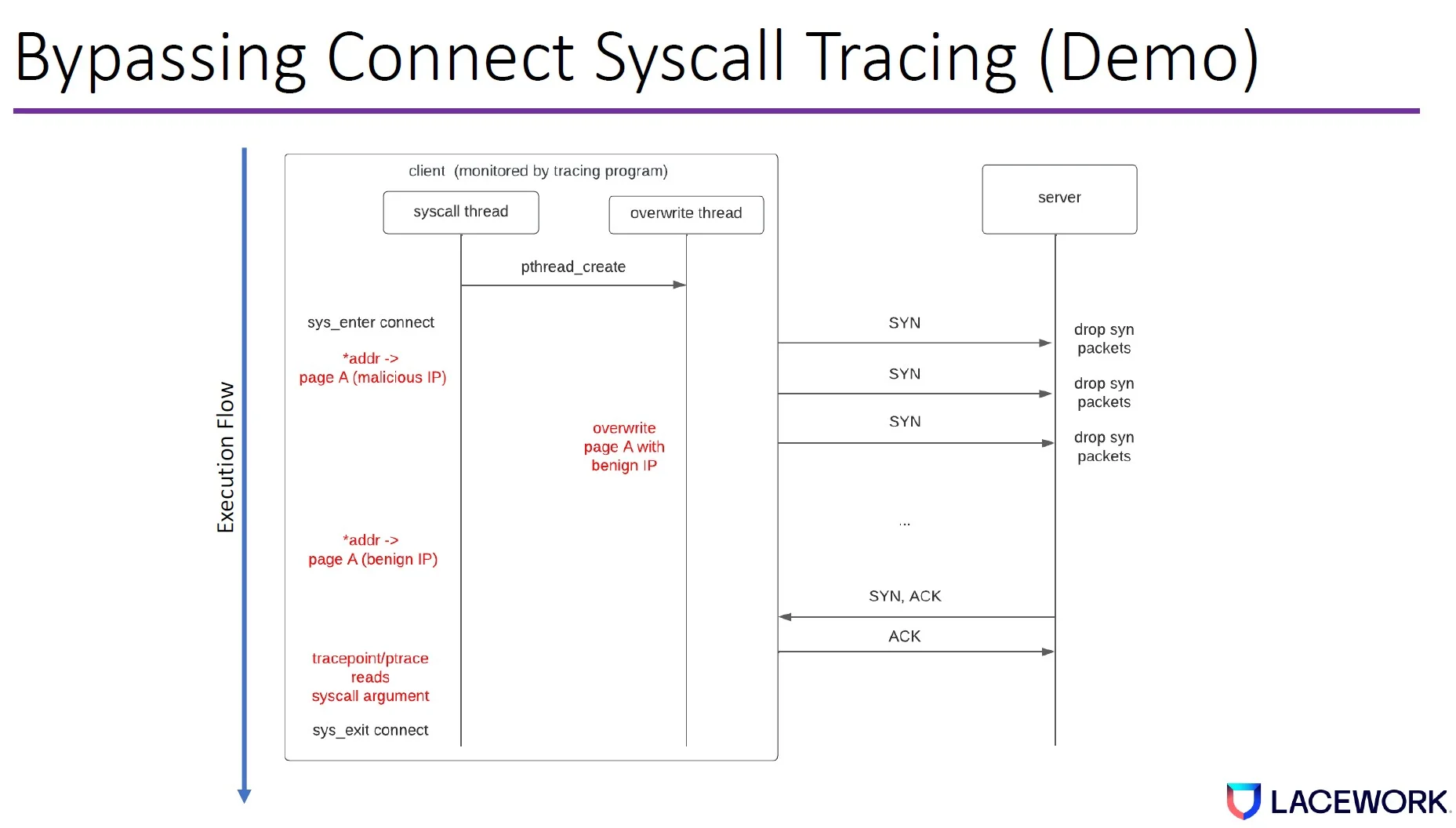
This gives the attacker an opportunity to control the server. This is common because attackers usually connect to the command and control server once they compromise a machine.
The attacker then runs a syscall thread on the client machine, which creates an overwrite thread. The syscall thread issues a connect syscall with an address pointer pointing to a memory page that contains the malicious IP. The client machine will then send a SYN packet to the server.
However, if the server drops the SYN packet, the client machine will retry the SYN packet. The delay will exponentially increase every time it retries based on the transmission control protocol (TCP) congestion control algorithm.
During the SYN retry, the overwrite thread overwrites the memory page with a benign IP. When the SYN, ACK comes back, the client machine sends the ACK. Then Tracepoint/ptrace will read our benign IP from the memory and exit the syscall.
Case study 2: File system syscalls
File system in user space (FUSE) is a filesystem framework, containing a kernel module (fuse.ko), a userspace library (libfuse.*), and a mount utility (fusermount). In cloud scenarios, it can be used for remote storage. It allows users to mount cloud objects as local file systems and access the objects as local files.
Remote storage FUSE are used in cloud native environments. Below are a few examples.
- gcsfuse: developed by Google for Google Cloud Storage (GCS)
- S3fs-fuse: developed by Randy Rizun for Amazon S3
- BlobFuse: developed by Azure for Blob Storage
- MezzFS: developed and deployed at Netflix
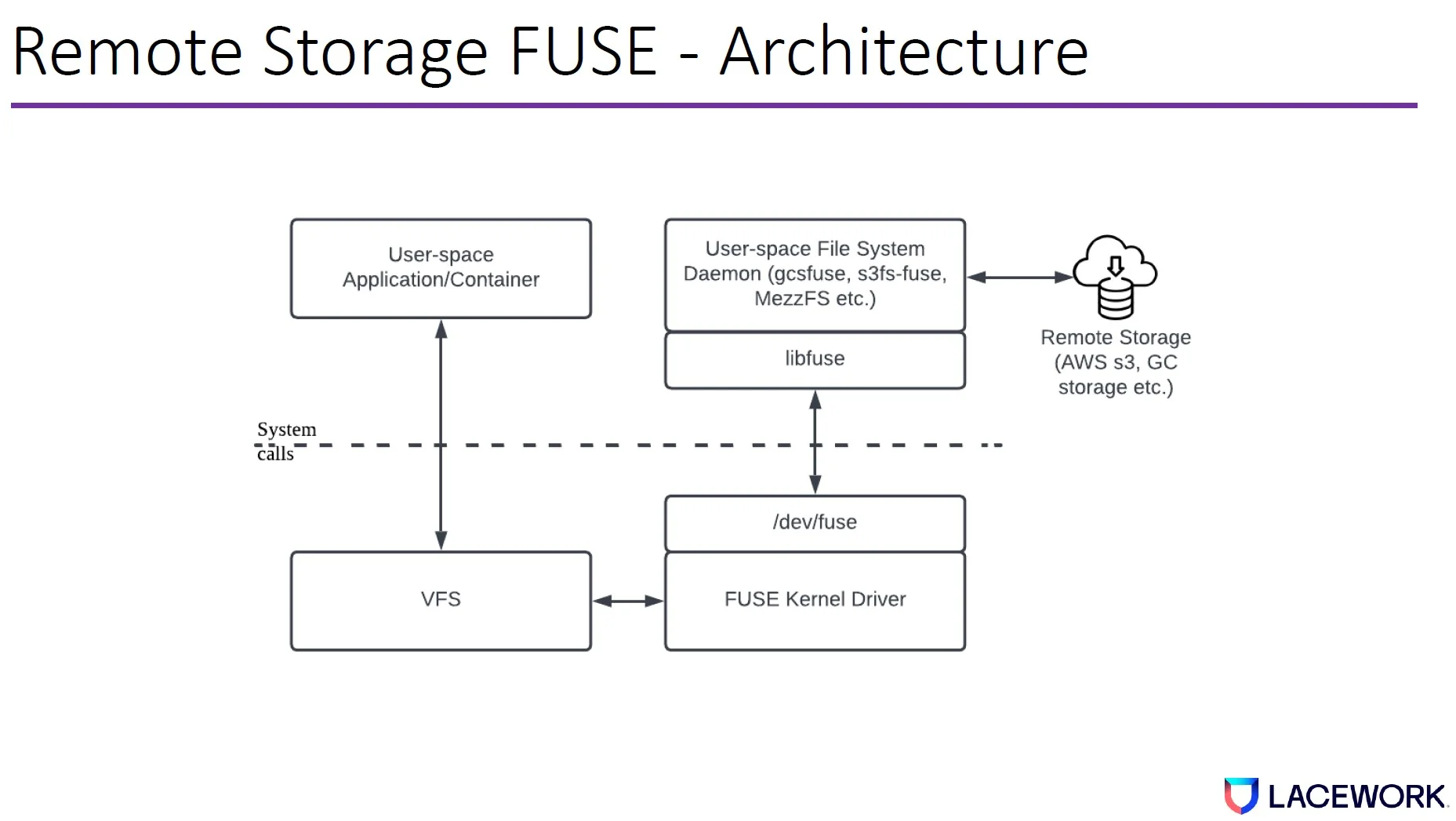
To open remote storage (e.g., AWS S3), the application will issue an openat syscall to the kernel—this is equivalent to opening a local file. The openat syscall request is routed from the kernel virtual file system, FUSE kernel driver, to userspace daemon (gcsfuse), and finally, it reaches remote storage.
Once the response is received, it will be sent back to the application/containers through the original path. The delay between the client and remote storage is much longer than the syscall delay in the client. We can leverage this delay to bypass openat syscall tracing.
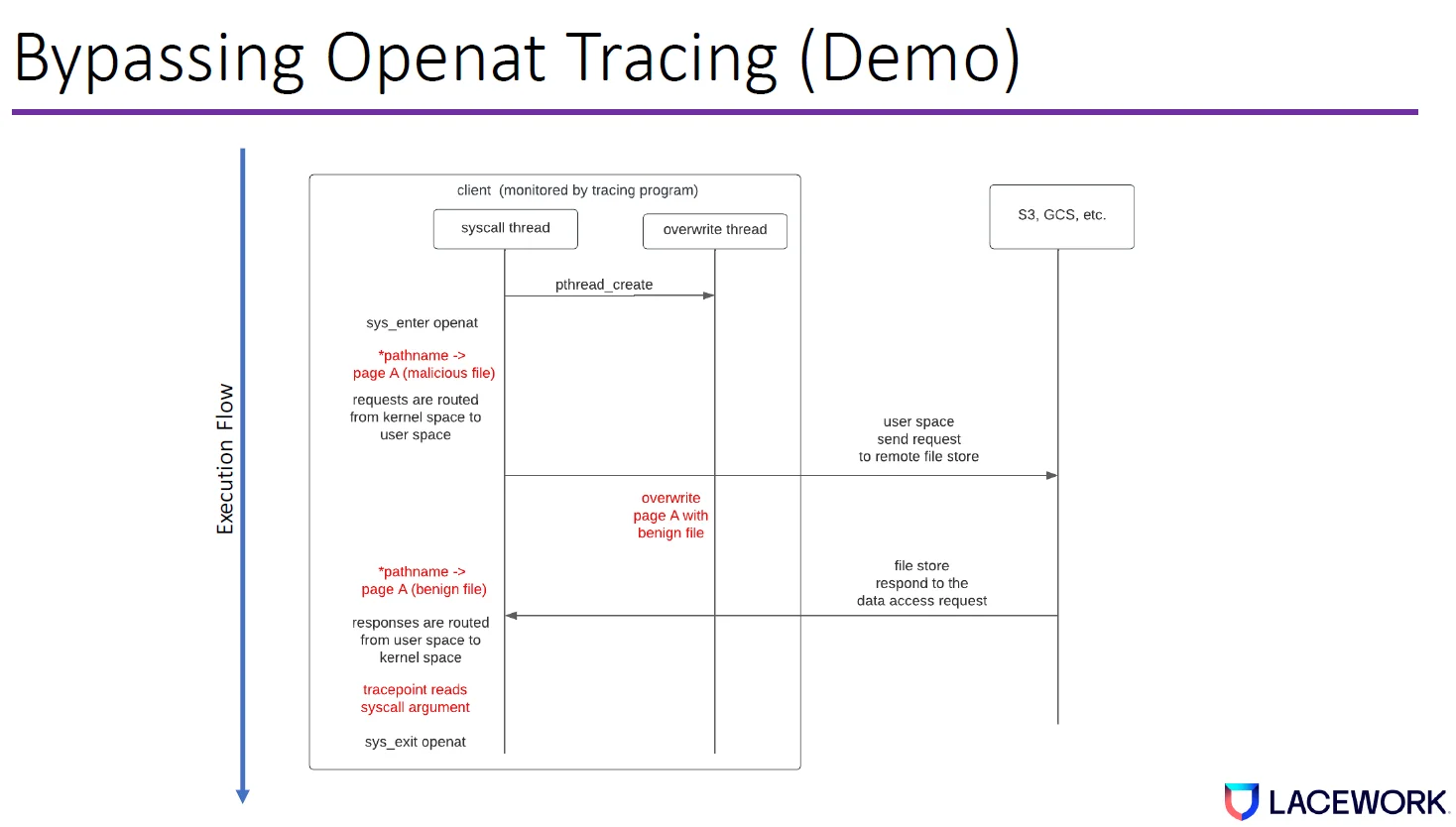
We will use openat syscall as an example to demonstrate the bypass when FUSE is used. When a tracing program monitors a malicious client, the syscall thread will open a remote file called malicious_file through FUSE. Basically, it issues an openat system call with the pathname pointer pointing to malicious_file in userspace.
FUSE routes the openat request from kernel space to userspace, and finally, to remote file storage.
Before the response is sent back from remote storage, the overwrite thread jumps in and overrides user memory from malicious_file to a benign file name. Again, because the delay is so long compared to syscall, the CPU has enough time to propagate the changes to all copies in the cache and memory.
After the response is back and before the syscall returns to userspace, the tracing program uses sysexit tracepoint to get the pathname in userspace, which has been changed from malicious file name to benign file name.
This means that our openat syscall tracing bypass succeeded.
Case study 3: Sys_enter bypass
Seccomp is a kernel-level mechanism to restrict syscalls. Modern sandboxes heavily rely on seccomp. Seccomp allows developers to write rules to allow/block certain syscalls. You can also allow syscalls based on argument variables.
As previously mentioned, Seccomp sits between ptrace sys_enter and the kernel functions that reads the user space arguments.
Can we use seccomp to TOCTOU the ptrace sys_enter monitoring?
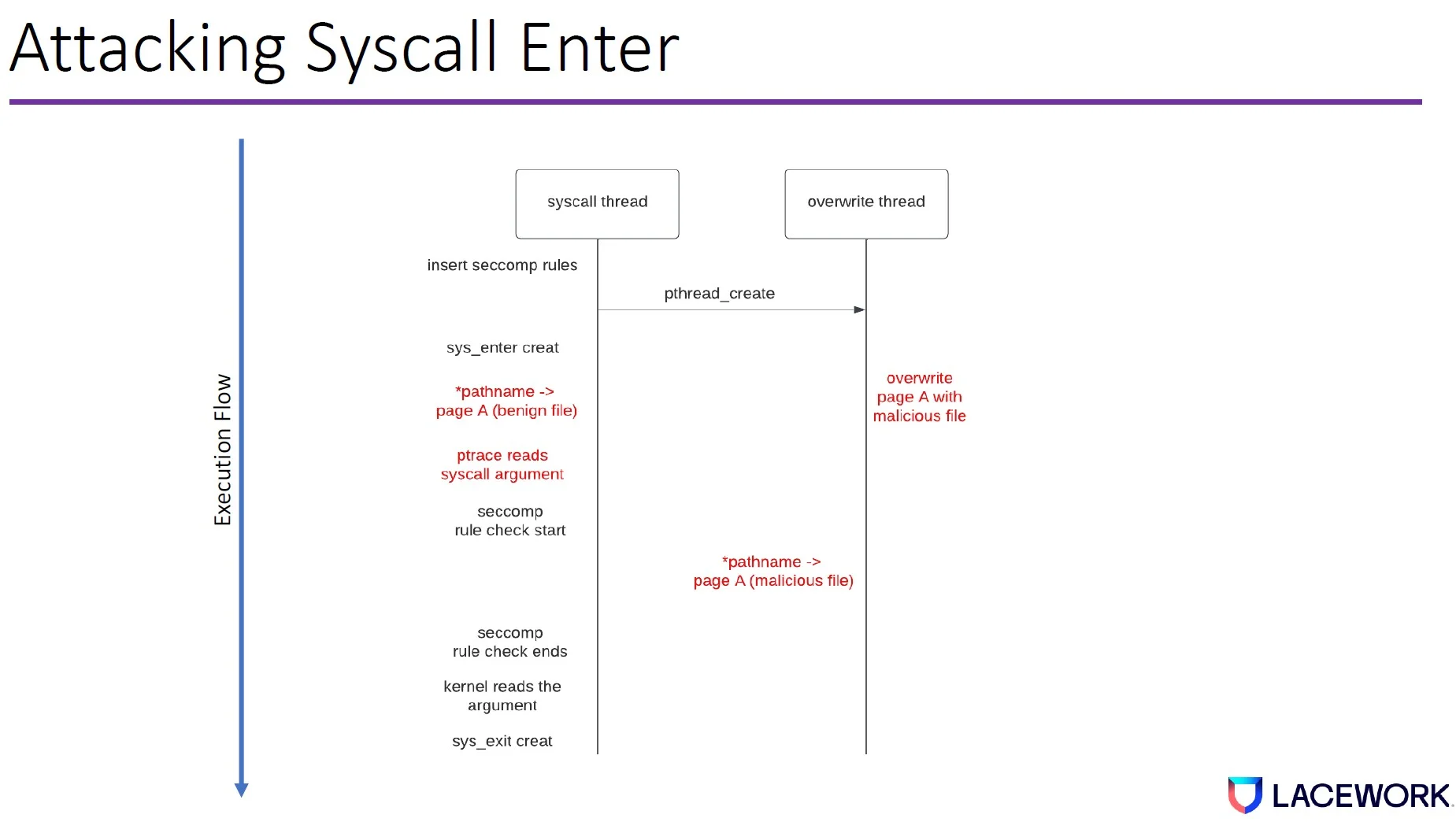
To bypass the ptrace sys_enter tracing, the attacker first uses the syscall thread to insert several seccomp filters. Then it creates an overwrite thread.
It triggers the syscall creat with the pathname pointer pointing to a benign file. The ptrace will read the syscall argument as a benign file.
Then the seccomp file check starts; while the seccomp rule check is being computed, the overwrite thread will overwrite page A with a malicious file.
When the seccomp rule finishes, the kernel will read the malicious file as the argument.
The impact
Any security monitoring software that uses tracepoint at sys_exit and ptrace are likely impacted unless special mitigations are already in place. These findings impact monitoring software running on any Linux endpoints, including cloud workloads. For sys_exit, most of the important syscalls are impacted. For sys_enter, all syscalls are impacted when ptrace is used. The sys_enter and sys_exit bypass also allows malware to bypass Linux sandbox solutions that rely on ptrace to collect malware artifacts.
We have released our POC exploit, and you can evaluate your environment with our tools.
Mitigations
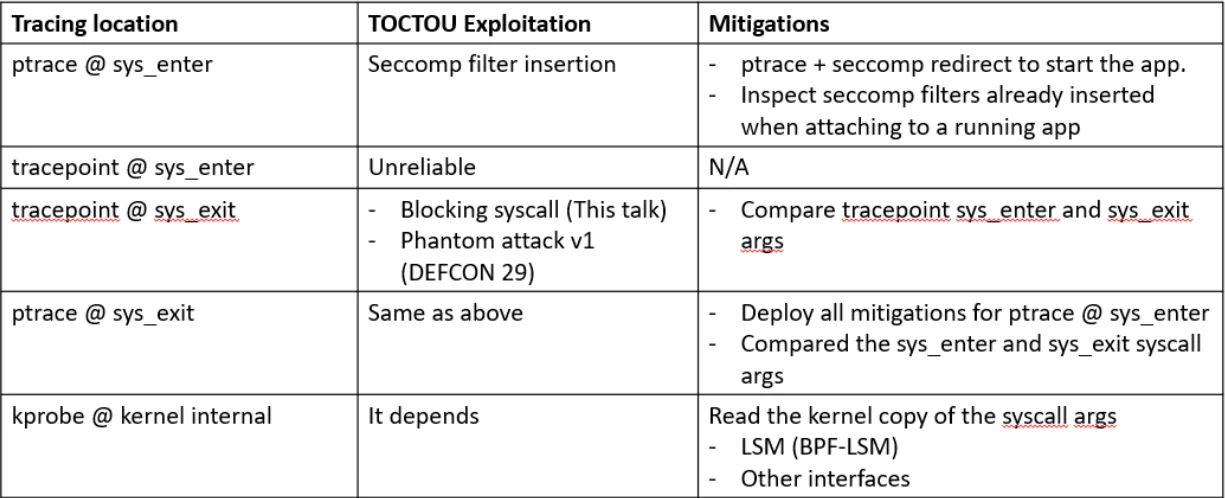
Ptrace at sys_enter is vulnerable to seccomp filter insertion. If the tracer starts the app, then the ptrace + seccomp redirect can fully mitigate the issue. If tracer attaches to a running app, then it needs to analyze the seccomp rules inserted by the application to look for an abnormal number of rules.
We are unaware of any exploit that can reliably bypass Tracepoint at sys_enter.
Tracepoint at sys_exit can be exploited by blocking syscall and the phantom attack v1 that we described at DEF CON 29. One can compare the tracepoint sys_enter and sys_exit arguments.
Ptrace at sys_exit is vulnerable to the same exploits as attack tracepoint sys_exit. You can deploy all the mitigations for ptrace at sys_enter and compare the sys_enter and sys_exit call arguments.
Because kprobe at an internal kernel function can hook into most kernel functions, mitigation depends on whether the TOCTOU window exists. The Linux Security Model (LSM) interface is a promising option. To support a wide range of kernel versions, the LSM hook coverage can vary. You might need to look into other kernel functions but be aware that they may change across kernel versions.
Summary
Many cloud customers rely on open source software solutions and assume their workloads are safe; however, vulnerabilities in the ways that security monitoring software uses Linux kernel mechanisms could enable attackers to go undetected. Lacework Labs did not analyze proprietary software and mitigations for these complex attacks, so we recommend checking your tools’ mitigation claims to ensure they have mitigated the issues properly. Security teams should also correlate different data sources to significantly increase the evasion complexity.
New attacks that take advantage of this security monitoring bypass will be invented in the future. But if your security teams know the baseline of your environment, and can distinguish what’s normal from what’s not, it will be much more difficult for attackers to evade detection.
To see more content like this, follow Lacework Labs on LinkedIn, Twitter, and Youtube and stay up to date on our latest research.
Categories
Suggested for you