5 best practices for securing Kubernetes runtime workloads
While hardening Kubernetes workload configuration or Kubernetes Role-Based Access Controls (RBAC) is a necessary best practice, it is just the tip of the iceberg when securing Kubernetes clusters. Kubernetes security posture management (KSPM) helps minimize the attack surface but does little to protect containers against runtime security issues.
The Red Hat 2022 State of Kubernetes security report states that “93% of respondents experienced at least one security incident in their Kubernetes environments in the last 12 months,” with almost one in three reporting they had experienced revenue or customer loss directly due to the incident.
A comprehensive Kubernetes security strategy requires a defense-in-depth approach that is able to detect attacks in-progress, unusual behavior, and attempts to exploit misconfigurations or vulnerabilities in running clusters. This level of visibility is also essential for complying with regulations and frameworks including SOC 2, NIST 800-53, CIS Benchmark for Kubernetes, PCI DSS, and ISO 27001.
Doing this requires visibility into the Kubernetes’ container layer to capture running processes, network layer to capture east-west (internal) and north-south (external) traffic, and at the API layer to capture user and machine activity.
Here are five best practices for securing Kubernetes workloads at runtime:
1. Monitor network connections
It is critical to understand and control how Kubernetes workloads and namespaces interact with each other, and external cloud resources or public APIs. Doing this means having an up-to-date map of all network connections, showing both internal and external traffic. Most compliance frameworks require this level of visibility as a prerequisite to understanding the critical path to sensitive services such as databases and vaults.
By baselining what normal network traffic looks like, it is possible to detect unusual traffic patterns that result from compromised applications or lateral movement associated with attacks in-progress. For example, a rogue container might try to discover weaknesses in an environment by performing network or port scans. In addition to new network traffic, this would generate a number of new failed and unauthorized connections that should be flagged as suspicious.
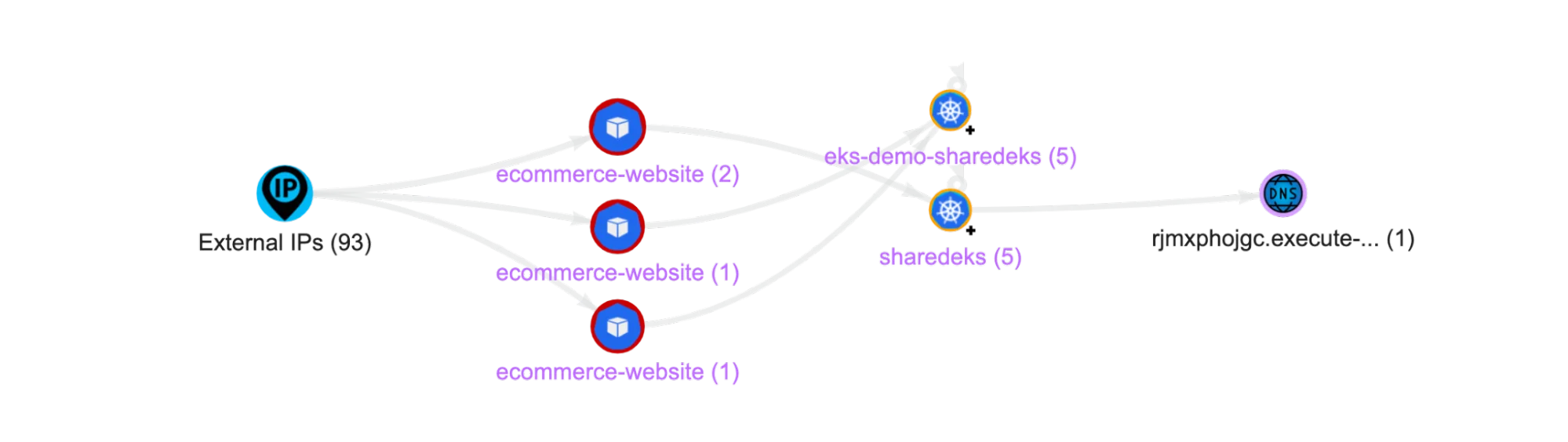
Lacework Kubernetes Polygraph: New network connections to Kubernetes pods detected
Attackers leveraging a rogue container or vulnerable applications will often connect to malicious endpoints to download malware, hacking tools, or exfiltrate data. Therefore, it is important to monitor the reputation of public IPs and domains that clusters access. Cryptominers can often be detected by identifying connections to known crypto pools and malicious sites.
Unfortunately, Kubernetes does not provide out-of-the-box tools for monitoring network connections. An important aspect of monitoring Kubernetes network connections is the ability to use the identity of workloads (i.e., namespace, workload name, pod name) to define where connections both originate (sources) and terminate (targets), rather than their internal IP address.
2. Monitor ingress endpoints
Kubernetes makes it easy to add an external load balancer or an ingress controller to expose internal workloads to the public internet. And as such, DevOps teams are very concerned about developers accidentally exposing a service that lacks the proper authentication and authorization required for public-facing endpoints. A large vehicle manufacturer accidentally exposed their Kubernetes dashboard to the internet without any kind of authentication enabled, which let attackers launch rogue pods in their clusters that took several months to detect.

Lacework Alert: Kube-system namespace exposed by new load balancer
All new ingress endpoints, such as external load balancers, ingress controllers, node ports, etc., must be tracked and validated. Any new ingress traffic identified from the internet to a workload should immediately raise an alert, to prevent unintended exposure. This information can also be correlated with the network map to check if any public-facing services have direct access to sensitive resources such as internal S3 buckets, databases, or vaults.
3. Monitor Kubernetes audit logs
A best practice for protecting container workloads is to define them using Infrastructure as Code (IaC) and restrict or minimize potentially unsafe activities like logging into a container (kubectl exec), and manual deletion of resources or changes to Kubernetes RBAC. Recent NSA/CISA Kubernetes Hardening Guidance, as well as the CIS Benchmark for Kubernetes and NIST 800-53, strongly recommend leveraging Kubernetes audit logs to detect risky activities.
However, manual changes can be hard to identify by only looking at a Kubernetes cluster configuration, and impossible to tie them back to a user. To do this, organizations must use Kubernetes audit logs (a.k.a. Kubernetes control plane logs), that record all Kubernetes API calls including user activities and automated workflows.
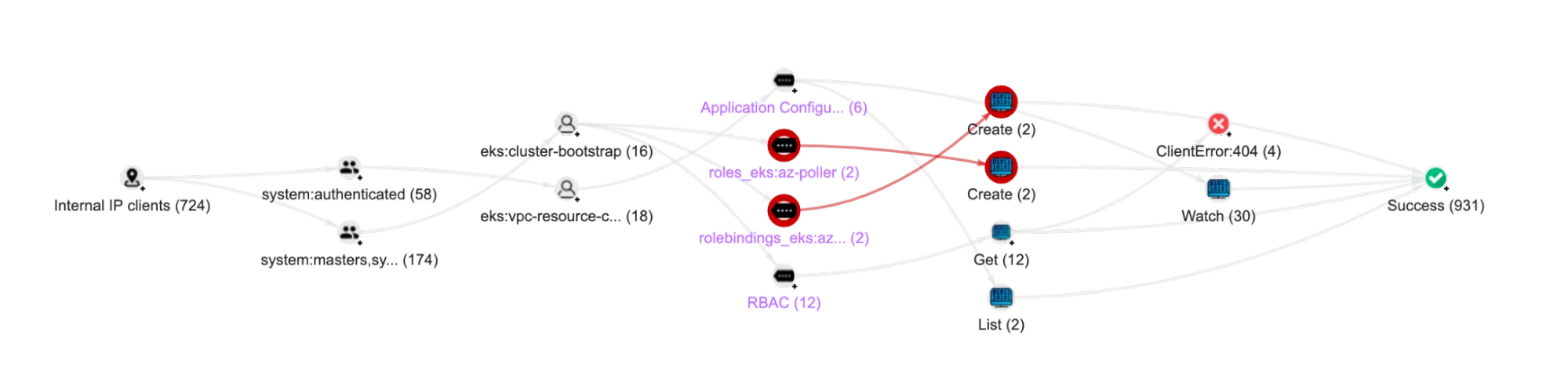
Lacework Audit Log Polygraph: New Kubernetes roles detected
But because a cluster can generate a million logs a day, mostly for normal activities, organizations need a highly scalable and intelligent solution that can automatically separate the signal from the noise and detect unusual behaviors, including:
- Remote access into containers: kubectl exec, kubectl attach (ephemeral container), and kubectl log
- Manual changes to running container images, including installation of packages and libraries
- Changes to or creation of roles, role bindings, cluster roles, or cluster roles bindings
- Running commands, like ‘kubectl portforward’, to bypass Kubernetes network policy and expose a container to the network.
Changes to RBAC are difficult to monitor without using audit logs. A standard Kubernetes environment includes over 20 default roles and 75 cluster roles, making it nearly impossible to detect, in real time, if the default RBAC was modified, or unsafe bindings were added. It is much more practical to observe, review and validate changes to Kubernetes RBAC through the audit logs.
Kubernetes Audit Logs are also extremely helpful for tracking failed API calls due to a lack of authentication, wrong permissions, or misconfiguration.
4. Monitor the deployment of new Kubernetes components and workloads
While ensuring container workloads are not privileged, and pods are not running as root or sharing host resources (PID, ICP, network, file system, etc.) are key to minimizing risk, many have learned, the hard way, that malicious containers, like rogue cryptominers, would not have been detected by checking for these types of elevated permissions.
Effectively securing container workloads requires going well beyond hardening Kubernetes configuration. It demands the ability to automatically detect container images that are pulled from new registries and new repositories (public registries such as Docker Hub and Quay are used to host many popular open-source Kubernetes applications). It must also detect workloads deployed by new users and those deployed outside the normal Continuous Integration Continuous Deployment (CI/CD) process that would bypass required security checks.

Lacework Alert: New privileged workload detected
5. Detect unknown Kubernetes threats
Monitoring network connections, ingress endpoints, audit logs and new workloads, provides in-depth security and compliance visibility across each layer (Kubernetes API, workloads and containers) of the Kubernetes environment. This provides the ability to spot known threats like connections to bad IPs, unintended ingress exposure, manual changes, and new unauthorized containers. But what about the unknown threats lurking within Kubernetes environments that you don’t know to look for?
Detecting these unknown unknowns requires first knowing what normal behavior looks like across the control and data planes of your Kubernetes environment. Since Kubernetes environments are highly dynamic, what’s normal next week will likely be different than today, and as such, your baseline of events and activities must be continually updated to reflect ongoing changes within your environment.
Doing this requires the continuous collection and correlation of massive amounts of data. As previously mentioned, a single cluster can generate a million logs per day. Sifting through this data manual is impossible, and requires the use of intelligent, noise-canceling behavioral analytics, that run unsupervised. This way you can automatically analyze application behaviors (file access, network traffic, processes), user activity (new workloads, changes to RBAC, remote access to pods), and Kubernetes activities (pod restart, health checks, miscellaneous errors).

Lacework Alert: Suspicious application detected in a running container
And while there are a number of different anomaly detection models out there, using one that compares you to you will provide the best results for your specific Kubernetes workloads. Detecting unusual behaviors and suspicious events, without having to write and maintain an endless set of rules, enables teams to quickly identify and investigate threats and avoid drowning in false positive alerts.
Spotting zero-day vulnerabilities like “log4j” and “cr8escape” could be achieved by detecting abnormal behaviors and events, such as new network connections to new public IPs and domains, for command and control (C2) communications, and lateral movement between containers and nodes.
Start securing Kubernetes runtime environments
While the proper configuration of Kubernetes, nodes, containers, and clusters is an essential best practice for reducing the attack surface, protecting Kubernetes runtime environments requires a defense-in-depth approach that includes monitoring network connections, ingress endpoints, audit logs, and new containers and workloads. It also requires the ability to detect unknown and in-progress threats that are associated with unusual behavior, anomalous events and any attempt to exploit misconfigurations or vulnerabilities in running clusters.
Discover more ways to properly secure your Kubernetes environments in our 10 security best practices for Kubernetes ebook.
Suggested for you